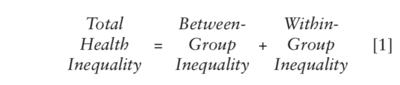Methods for forecasting mortality rates (overall or for time series data cross-classified by age, sex, country, and cause); estimating mortality rates in areas without vital registration; measuring inequality in risk of death; applications to US mortality, the future of the Social Security, armed conflict, heart failure, and human security.
Zachary J. Ward, Rifat Atun, Gary King, Brenda Sequeira Dmello, and Sue J. Goldie. 4/20/2023. “A simulation-based comparative effectiveness analysis of policies to improve global maternal health outcomes.” Nature Medicne. Publisher's VersionAbstract

The Sustainable Development Goals include a target to reduce the global maternal mortality ratio (MMR) to less than 70 maternal deaths per 100,000 live births by 2030, with no individual country exceeding 140. However, on current trends the goals are unlikely to be met. We used the empirically calibrated Global Maternal Health microsimulation model, which simulates individual women in 200 countries and territories to evaluate the impact of different interventions and strategies from 2022 to 2030. Although individual interventions yielded fairly small reductions in maternal mortality, integrated strategies were more effective. A strategy to simultaneously increase facility births, improve the availability of clinical services and quality of care at facilities, and improve linkages to care would yield a projected global MMR of 72 (95% uncertainty interval (UI) = 58–87) in 2030. A comprehensive strategy adding family planning and community-based interventions would have an even larger impact, with a projected MMR of 58 (95% UI = 46–70). Although integrated strategies consisting of multiple interventions will probably be needed to achieve substantial reductions in maternal mortality, the relative priority of different interventions varies by setting. Our regional and country-level estimates can help guide priority setting in specific contexts to accelerate improvements in maternal health.