Statistically Valid Inferences from Differentially Private Data Releases, With Application to the Facebook URLs Dataset
Abstract
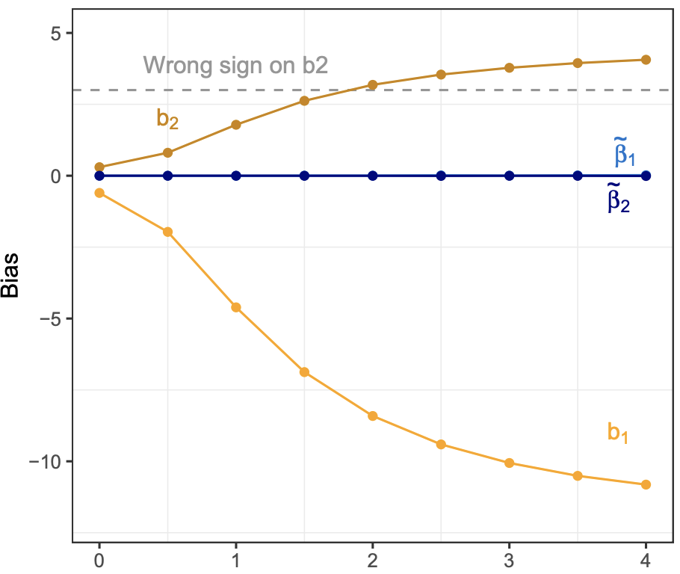
We offer methods to analyze the “differentially private” Facebook URLs Dataset which, at over 40 trillion cell values, is one of the largest social science research datasets ever constructed. The version of differential privacy used in the URLs dataset has specially calibrated random noise added, which provides mathematical guarantees for the privacy of individual research subjects while still making it possible to learn about aggregate patterns of interest to social scientists. Unfortunately, random noise creates measurement error which induces statistical bias – including attenuation, exaggeration, switched signs, or incorrect uncertainty estimates. We adapt methods developed to correct for naturally occurring measurement error, with special attention to computational efficiency for large datasets. The result is statistically valid linear regression estimates and descriptive statistics that can be interpreted as ordinary analyses of non-confidential data but with appropriately larger standard errors.
We have implemented these methods in open source software for R called PrivacyUnbiased. Facebook has ported PrivacyUnbiased to open source Python code called svinfer. We have extended these results in Evans and King (2021).
See Also
- [Dataset] Replication Data for: Statistically Valid Inferences from Differentially Private Data Releases, with Application to the Facebook URLs Dataset
- [Paper] Differentially Private Survey Research (2024)
- [Paper] Letter to US Census Bureau: 'Request for Release of 'noisy Measurements File' by September 30 Along With Redistricting Data Products' (2021)
- [Paper] Statistically Valid Inferences from Privacy Protected Data (2023)
- [Paper] There's a Simple Solution to the Latest Census Fight (2021)
- [Paper] Statistically Valid Inferences from Differentially Private Data Releases, II: Extensions to Nonlinear Transformations (2025)
- [Presentation] Statistically Valid Inferences from Privacy Protected Data (Pew Research Center) (2025)
- [Presentation] Statistically Valid Inferences from Privacy Protected Data (Stat188, Harvard University) (2024)