
Comparative Effectiveness of Matching Methods for Causal Inference
Abstract
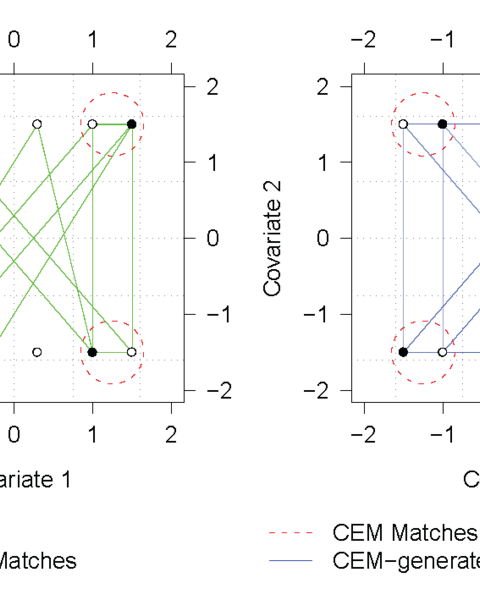
Matching is an increasingly popular method of causal inference in observational data, but following methodological best practices has proven difficult for applied researchers. We address this problem by providing a simple graphical approach for choosing among the numerous possible matching solutions generated by three methods: the venerable “Mahalanobis Distance Matching” (MDM), the commonly used “Propensity Score Matching” (PSM), and a newer approach called “Coarsened Exact Matching” (CEM). In the process of using our approach, we also discover that PSM often approximates random matching, both in many real applications and in data simulated by the processes that fit PSM theory. Moreover, contrary to conventional wisdom, random matching is not benign: it (and thus PSM) can often degrade inferences relative to not matching at all. We find that MDM and CEM do not have this problem, and in practice CEM usually outperforms the other two approaches. However, with our comparative graphical approach and easy-to-follow procedures, focus can be on choosing a matching solution for a particular application, which is what may improve inferences, rather than the particular method used to generate it.
Please see our follow up paper on this topic: Why Propensity Scores Should Not Be Used for Matching.
See Also
- [Paper] A Theory of Statistical Inference for Matching Methods in Causal Research (2019)
- [Paper] Causal Inference Without Balance Checking: Coarsened Exact Matching (2012)
- [Paper] CEM: Coarsened Exact Matching in Stata (2009)
- [Paper] CEM: Software for Coarsened Exact Matching (2009)
- [Paper] Matching As Nonparametric Preprocessing for Reducing Model Dependence in Parametric Causal Inference (2007)
- [Paper] MatchIt: Nonparametric Preprocessing for Parametric Causal Inference (2011)
- [Paper] Multivariate Matching Methods That Are Monotonic Imbalance Bounding (2011)
- [Paper] The Balance-Sample Size Frontier in Matching Methods for Causal Inference (2017)